N+1 Queries: Como corrigir

Consultas N+1 são uma armadilha comum de desempenho ao usar Object-Relational Mappers (ORMs), como o Django ORM e o Prisma, em aplicações web. Este artigo explica o que são consultas N+1, por que elas afetam o desempenho e como corrigi-las na prática em bases de código que usam Django e Prisma.
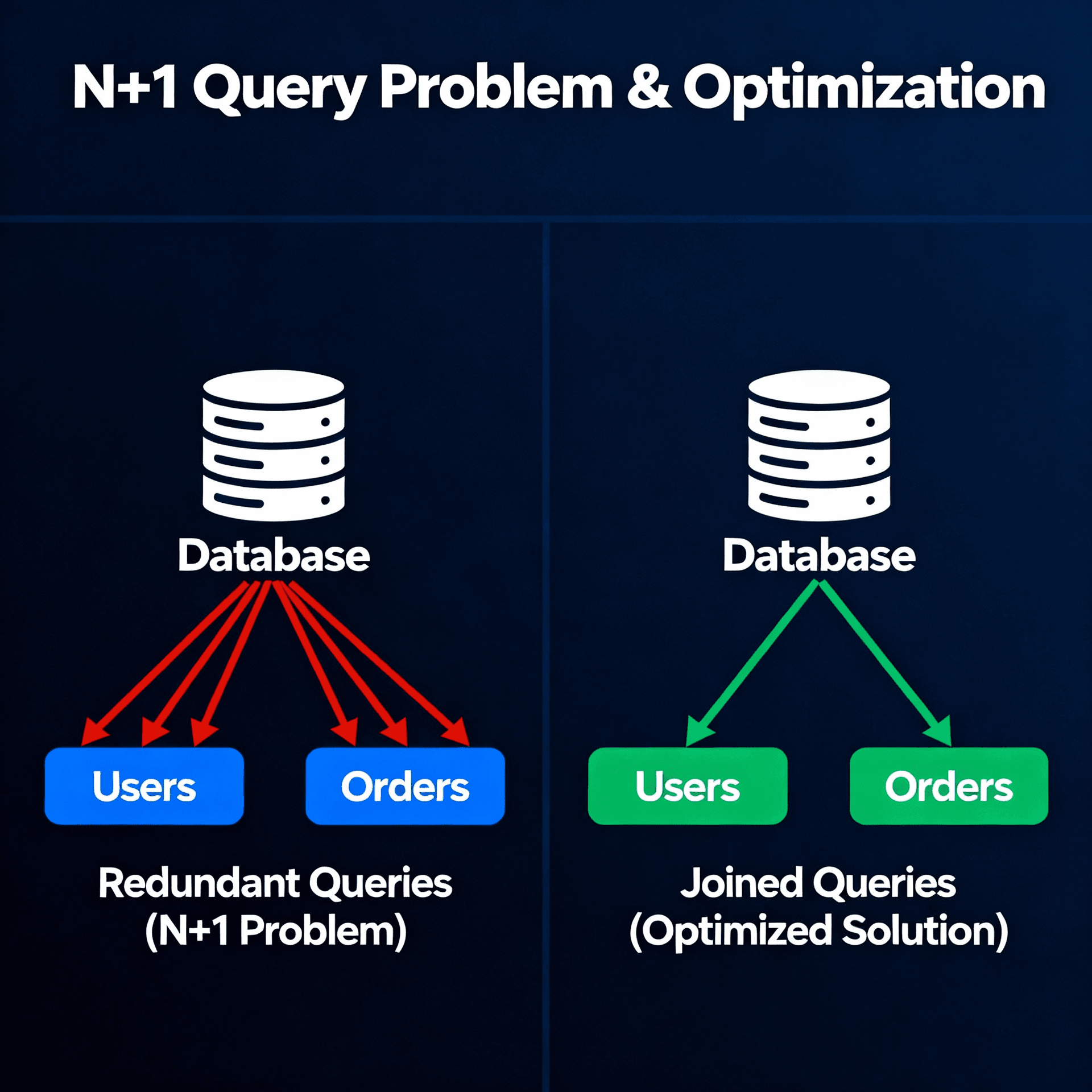
O que é uma Consulta N+1?
O padrão de “consulta N+1” ocorre quando uma consulta inicial busca uma lista de itens, e em seguida uma nova consulta é executada para cada item a fim de buscar dados relacionados. Isso resulta em um total de N+1 consultas (N sendo o número de itens). Esse padrão ineficiente normalmente aparece quando ORMs carregam objetos relacionados de forma preguiçosa dentro de loops, o que gera várias idas desnecessárias ao banco de dados e torna a aplicação mais lenta.
Exemplo em Django:
for w in ProgramWorkout.objects.all():
print(w.id, w.program.id) # Isso dispara uma nova consulta para cada w.program (N+1 consultas)
Aqui, uma consulta busca todos os objetos ProgramWorkout, mas cada acesso ao programa relacionado gera outra consulta, totalizando N+1 consultas.
| Ruim | Bom |
|---|---|
 |
 |
Soluções no Django: select_related e prefetch_related
O Django fornece duas ferramentas poderosas do ORM para resolver problemas de N+1:
- select_related: Usa um JOIN SQL para buscar objetos relacionados em uma única consulta. Ideal para relações do tipo ForeignKey e OneToOne.
ProgramWorkout.objects.select_related('program').all() - prefetch_related: Executa uma consulta adicional para buscar todos os objetos relacionados de múltiplos itens principais e os une em memória Python. Ideal para relações reversas de ForeignKey e ManyToMany.
ProgramWorkout.objects.prefetch_related('programworkoutExercise_set').all()
Use select_related para relações de valor único (onde cada item tem apenas um objeto relacionado) e prefetch_related para relações de múltiplos valores ou reversas (onde vários objetos compartilham itens relacionados).
Soluções no Prisma para Consultas N+1
Problemas de N+1 similares ocorrem no Prisma ao buscar dados relacionados em consultas separadas. O Prisma oferece diversas maneiras de corrigir isso:
- Use include para fazer carregamento antecipado (eager loading) dos campos relacionados em uma ou poucas consultas.
const workouts = await prisma.programWorkout.findMany({ include: { program: true, programWorkoutExercise: true, }, }); - Ative relationLoadStrategy: "join" para realizar junções (joins) no banco de dados internamente, reduzindo o número de consultas para apenas uma.
- O dataloader interno do Prisma Client agrupa múltiplas consultas findUnique() que ocorrem no mesmo ciclo do event loop em uma única consulta SQL, otimizando padrões de resolvers GraphQL.
Essas técnicas reduzem o tráfego de rede, a carga no banco de dados e melhoram a experiência do usuário, evitando consultas excessivas.
Depurando Consultas N+1
- Desenvolvedores Django podem usar o Django Debug Toolbar para inspecionar consultas SQL por endpoint e detectar padrões N+1.
- Ferramentas de monitoramento como o New Relic também podem identificar padrões ineficientes de chamadas ao banco e revelar um alto número de consultas por transação.
- Usuários do Prisma podem ativar o log de consultas ou usar ferramentas de profiling para detectar consultas excessivas e otimizá-las.
Boas Práticas
- Sempre analise seu código em busca de riscos de consultas N+1 ao acessar dados relacionados em loops.
- Use select_related ou prefetch_related no Django, ou include e relationLoadStrategy no Prisma, conforme o tipo de relação do seu modelo de dados.
- Faça o profiling regular de suas APIs com ferramentas de inspeção de consultas para manter o desempenho ideal.

